
正如在介绍rarity.tools的文章中所指出的,在收藏NFT项目的Discord中,人们最常问的问题之一是’我的NFT有多稀有?’。
这是因为稀有性是决定单个NFT价值的最重要因素之一。
但是你如何确定单个NFT作品的整体稀有性?这就是本系列文章要(尝试)回答的问题。
疑问
如果你看一下OpenSea上的任何可收集的NFT物品,例如Bored Ape Yacht Club,你会发现它有许多属性(或特征)。
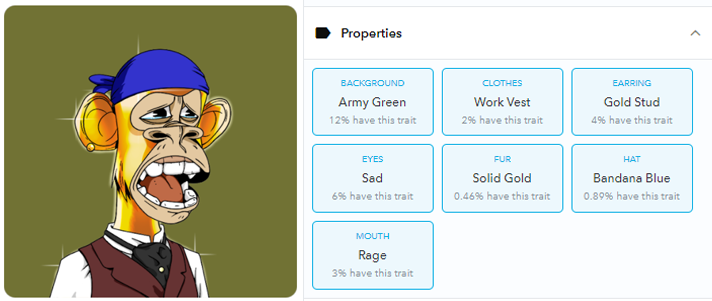
通过查看属性,你可能能够确定一个NFT具有一些罕见的特征。
但这个NFT与其他NFT相比有多罕见?当比较两个NFT时,你是否只是简单地比较每个NFT的最罕见的特征?
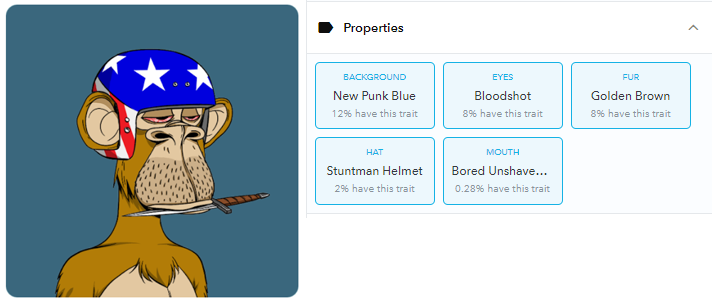
因为每个NFT都有多个特征,所以必须有一种方法将所有特征的稀有性合并为每个NFT的一个单一值,以便能够对它们进行实际排名。
人们有许多方法按稀有度对NFT进行排名。下面我们谈一谈其中的一些。
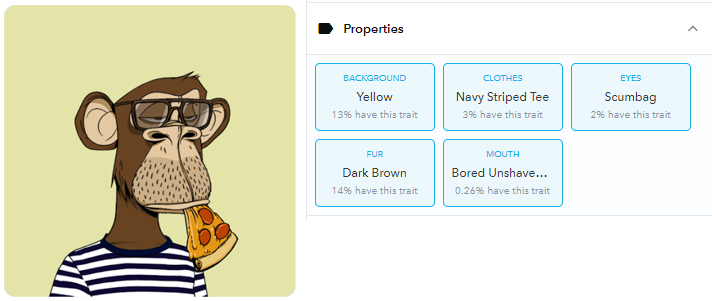
罕见特征稀有度排行
- 73号猿猴最稀有的特征是出售金毛,有0.46%的人拥有。
- 9941号猿猴最稀有的特征是无聊的无毛匕首,有0.28%的人拥有。
- 猿猴#9542最稀有的特征是无聊的不修边幅的披萨,有0.26%的人拥有。
使用 “罕见特征稀有度排名”,那么顺序将是#9542、#9941和最后的#73。
虽然这是一个简单明了的方法,但这个方法的弱点是它只考虑每个NFT的最罕见的特征。
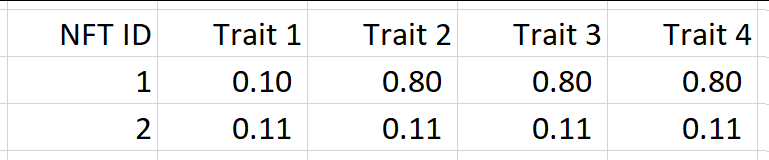
想象一下,我们有一个NFT的集合,每个NFT有4个性状。假设我们有2个NFT,我们想对其进行比较,如下表所示:
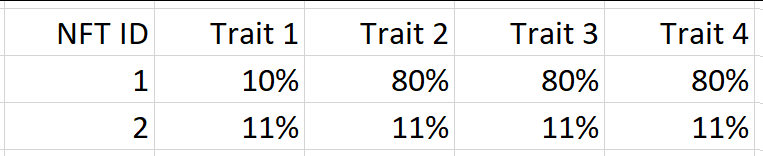
使用罕见特征稀有度,NFT ID 1会赢,因为它最稀有的特质(特质1)有10%的稀有度,低于NFT 2的任何特质。但是NFT 2的其他特征都比NFT 1的所有其他特征要稀少得多。总的来说,NFT 2不是更有价值吗?
这就是按特质稀有度排名的弱点。它根本不看NFT的整体稀有性,只看最稀有的特征。
平均特征稀有度
有时使用的另一种方法是对NFT上存在的特征的稀有性进行平均。
例如,如果一个NFT有两个特征,一个具有50%的稀有性,另一个具有10%的稀有性,那么它的平均特征稀有性将是(50+10)/2=30%。
就拿前面的Ape举例:
- Ape #73平均特性稀有度是4.05%。
- Ape #9941平均性状稀有度是6.056%。
- Ape #9542平均性状稀有度是6.452%。
因此,用这种方法,顺序将与之前的方法完全翻转。 排名将是第73位,第9941位,然后是第9542位。
平均特征稀有度有什么好处吗?好吧,至少它考虑了特征的整体稀有性。让我们再来看看前面那个有NFT ID 1和2的例子

所以NFT ID 2的平均稀有度是0.11,而NFT ID 1是0.625。这意味着平均稀有度说NFT ID 2比NFT ID 1更稀有。
这种方法的问题(接下来描述的统计稀有性也有这个问题)是,它对每个特征的总体稀有性的权重太高,具有单一超级稀有特征的NFT的价值不够高,因为它们的稀有性价值被其他特征过于 “稀释 “了。
为了说明这一点,设想我们有一个NFT的集合,看起来像这样:
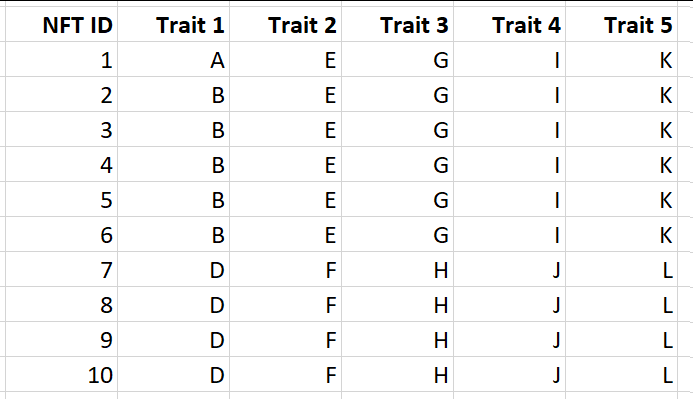
你认为哪一个是最稀有的?当然是NFT ID 1!
现在让我们尝试对它们使用特征稀有度排行和平均特征稀有度排行。首先,我们将特征值转换为其特征稀有度百分比。
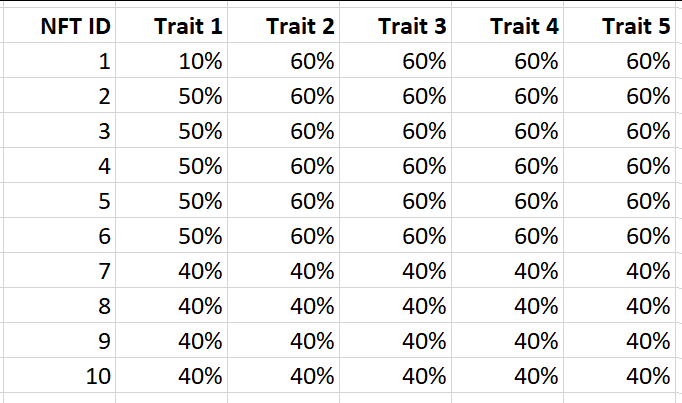
如果我们对这个系列使用特质稀有度排名,那么NFT ID 1将是最稀有的,这与我们认为应该是正确的一致。
现在让我们尝试使用平均特质稀有性
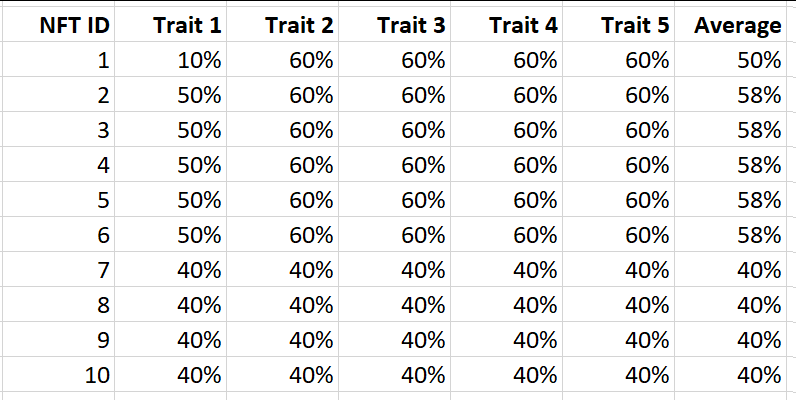
哦!原来平均特征稀有度排名认为NFT ID 7、8、9和10比NFT ID 1更稀有!。
但NFT ID 1是唯一的一个,是1中唯一的1,显然是收藏中最有价值的,不是吗?
这意味着也许平均稀有度排名毕竟不是一个真正的好方法?
统计学上的稀有度
现在让我们来看看统计学的稀有度,它已经成为一种有点流行的方法,在社区制作的电子表格中经常使用。
在统计学稀有度中,据我所知,这是由Adam Chekroud第一次写到NFT,你通过将所有的特征稀有度相乘来计算NFT的总体稀有性。
例如,如果一个NFT有两个特征,其中一个特征为10%,另一个特征为50%,那么该NFT的 “统计稀有性 “将是(10%*50%)=5%。
对于我们的3只ape,为了使结果合理,我们需要加上类人猿没有帽子的概率为22.56%,类人猿没有耳环的概率为70.23%,类人猿没有衣服的概率为18.8%。 可以说,在 “平均特质稀有性 “计算中也应该加上这些,但这不会改变最终结果,相反,它只会使结果更加极端。

- Ape #73统计稀有性是0.00000000070744%。
- Ape #9941统计稀有度是0.00000056965722%。
- Ape #9542统计稀有度是0.00000044983967%。
因此,用这种方法,排名将是第73位,第9542位,然后是第9941位。
在仅仅比较3只猿猴时,三种不同的方法有三种不同的结果。想象一下,当对10000个完整的集合进行排序时,它们之间的差异会有多大!
所有这些方法都是目前在社区制作的排名电子表格和网站中使用的方法。
因此,如果这篇文章不能说服你什么,它至少应该说服你,对NFT的稀有性进行排序是一个没有明显解决方案的问题。
统计学上的稀有度在实例集A和B的对比
现在让我们看看统计稀有性在我们测试特征稀有性和平均特征稀有性的两个例子集合中的表现。
首先让我们看看罕见稀有性失败的那个例子

在这里,它说NFT ID 2更稀有,这与平均特质稀有性相符,因此它通过了我们的第一个测试。
接下来让我们看看它对实例集B的表现如何
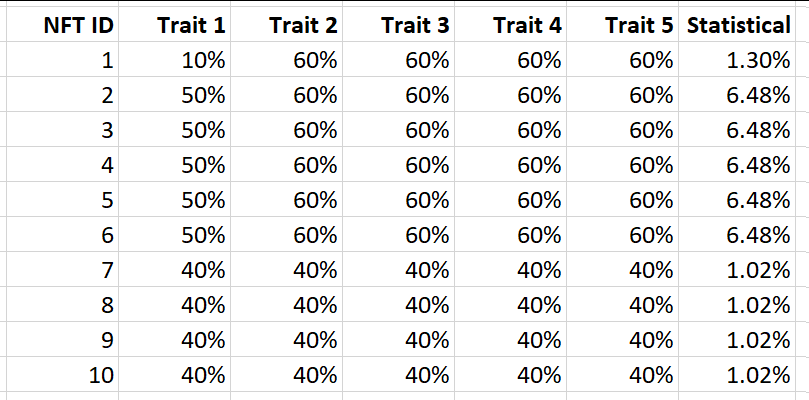
哦!就像平均性状稀有性一样,统计稀有性说NFT ID 7-10比NFT ID 1更稀有!但是ID 7-10是相互重复的。
但是ID7-10是相互重复的! 或者我们应该相信统计稀有性的结果,并出去以比NFT ID 1更高的价格购买ID 7-10?
但显然,NFT ID 1是1中唯一的1,如果你问大多数人,肯定也会认为它是最稀有的,因为没有任何其他类似的。
有些人可能会说’但我认为统计稀有性是’统计上正确的’?
问题是,通过将每个NFT特征的所有稀有性相乘,你并没有真正衡量一个NFT在特定NFT收藏中的稀有性。真正被衡量的是其他东西,我将留给读者去思考,因为这篇文章会变得比现在还要长。
让我们接下来看看稀有度得分。
稀有度评分:它是如何计算的?
那么,什么是稀有度得分?稀有度得分是我(rarity.tools的创始人)想出的一种方法。
计算稀有度分数的简单方法,在该网站上也有描述。
[某一特征值的稀有度得分] = 1 / ([具有该特征值的物品数量] / [收藏品的总数量])
一个NFT的总稀有度分数是它所有特征值的稀有度分数之和。
这个简单的计算方法给出了非常好的结果,今天也被用作其他NFT网站(包括NFT市场)的稀有性排名的基础。
因为[具有该特质值的物品数量]/[收藏品总数量]与特质稀有度相同(分数,不是%),我们也可以说
[特质值的稀有度得分]=1/[该特质值的稀有度]。
稀有度评分在实例集A和B中的对比
让我们继续看看Rarity Score是如何处理我们的两个问题例子的。
请记住,这些假想的NFT系列是非常简单的。如果我们使用的任何计算方法连这些都搞不定,那么我们怎么能相信我们的方法能把上万个NFT的集合搞好呢?
让我们从实例集合A开始。首先,我们以分数的形式写下性状的稀有性。
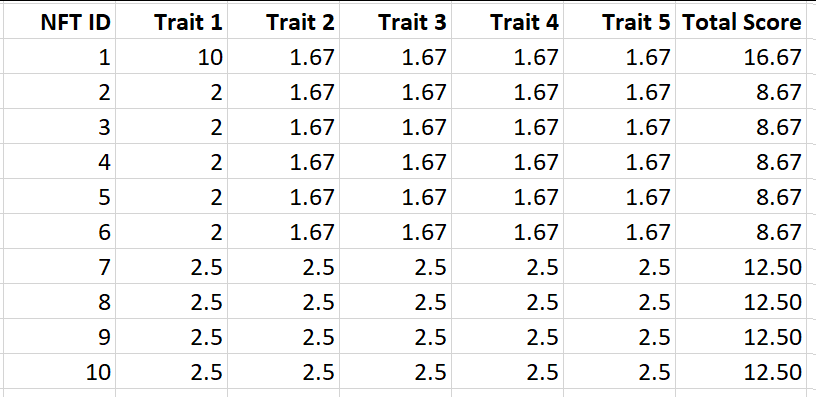
然后我们将它们转换为稀有性分数。例如,NFT ID 1特质1的稀有性分数是(1/0.1)=10,然后我们将每个NFT ID的分数加起来

所以稀有度得分说NFT ID 2更有价值,因为它有更高的分数。
接下来让我们看看它是如何处理实例集B的。我们将继续计算分数。
是的! 稀有度评分正确地将NFT ID 1列为最稀有的NFT,其次是NFT ID 7-10,然后是ID 2-6。
因此,我们在这里看到的是,在这两个例子中,稀有度评分方法给我们的结果与我们人类本能地选择哪个NFT更稀有相吻合,而统计稀有度和其他方法都失败了。
总结
如前所述,统计稀有性和平均稀有性有一种倾向,即过度强调NFT中所有性状的整体稀有程度,而对可能是整个系列中1中1的单一稀有性状则没有给予足够的重视。
另一方面,罕见特征稀有性的问题完全相反,它只考虑最稀有的特征。
稀有度评分给出的结果对单一稀有性状给予了足够的重视,同时也将整体性状的稀有度纳入其计算中。最重要的是,它给出的结果与我们人类的期望值更加匹配。
接下来是什么?
虽然计算方法是计算排名的最核心部分,但仍有许多额外的因素要被用来获得最佳的最终结果。
在接下来的文章中,我将写到性状标准化、唯一性、加权和使用组合性状以及可能的其他主题。
稀有度评分为什么或如何工作也是我可能会写的内容。
原文来源:https://raritytools.medium.com/ranking-rarity-understanding-rarity-calculation-methods-86ceaeb9b98c
本文原文非中文版本,由BruceX进行翻译,如若转载,请注明出处:https://www.iota.love/202204/ranking-rarity-understanding-rarity-calculation-methods/